Что такое облачные базы данных
Облачные базы данных — это готовое решение на основе Рег.облака, которое предназначено для работы с базами данных. Оно представляет собой кластер с предустановленной системой управления базами данных.
Для чего используются облачные базы данных
СУБД в облаке используются для выполнения сложных задач разных направлений. Облачная база данных будет полезна, если вы планируете:
- создать крупное веб-приложение,
- заниматься backend-разработкой систем CRM и ERP,
- автоматизировать документооборот в организации,
- использовать СУБД внутри WMS-систем учета складских операций.
Преимущества облачных баз данных
Решения с облачными базами данных:
- быстро запускаются — активация сервера занимает несколько секунд.
- легко масштабируются — повысить тариф сервера и добавить мощностей можно в любой момент;
- безопасны — благодаря этому в облаке можно хранить конфиденциальную информацию;
- удобно оплачивать, так как средства списываются за каждый час использования. Также по необходимости сервер можно остановить и запустить позже;
- не требуют вашего администрирования — после заказа вы получаете готовую облачную базу данных.
Как работает репликация
Принцип работы репликации зависит от предустановленной СУБД.
В PostgreSQL репликация работает в режиме «master-slave». В этом случае master-сервер имеет права на чтение и запись, а slave-сервер — только на чтение.
Если речь идет о MySQL, то репликация выполняется в режиме multi-master. В этом режиме все серверы репликации равнозначны и обладают правами на чтение и запись.
Что входит в наши обязанности при администрировании сервера
Компания Рег.ру берет администрирование сервера на себя. Что входит в зону ответственности наших технических специалистов:
- подготовка облака нужной конфигурации,
- развертывание сервера с выбранной СУБД,
- обновление и оптимизация серверного программного обеспечения.
Тарифы облачных баз данных
Для работы с облачными базами данных доступны пять тарифов.
Доступное программное обеспечение
Стек технологий
- cоздание облачного хранилища: OpenStack,
- автоматизация работы с контейнерами: Kubernetes,
- технология виртуализации: KVM.
Предустановленная СУБД
PostgreSQL: версии 13, 14, 15.
Что потребуется для создания кластера базы данных
Создание кластера базы данных происходит в пару кликов. Чтобы завершить заказ, вам потребуется:
- 1. Выбрать СУБД и ее версию.
- 2. Подобрать тариф с нужным объемом мощностей — при подборе опирайтесь на системные требования проекта.
- 3. Заполнить название кластера, имя базы данных, а также логин и пароль пользователя базы данных.
После этого дождитесь активации кластера.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊
Где найти информацию о кластере облачной базы данных
В статье мы расскажем о том, где найти доступы к облачной БД и другую информацию о кластере.
Данные можно найти двумя способами:
- в стартовом письме,
- в личном кабинете.
Рассмотрим каждый из них подробнее.
Как найти данные в стартовом письме
Стартовое письмо отправляется на ваш контактный email после создания кластера. В нем содержатся все необходимые данные для подключения и работы с СУБД. Информация из письма разделена на несколько блоков, которые мы опишем ниже.
Доступ к кластеру
В блоке «Доступ к кластеру» указаны:
- IP-адрес, на котором размещен кластер;
- порт для подключения;
- логин пользователя;
- пароль пользователя.
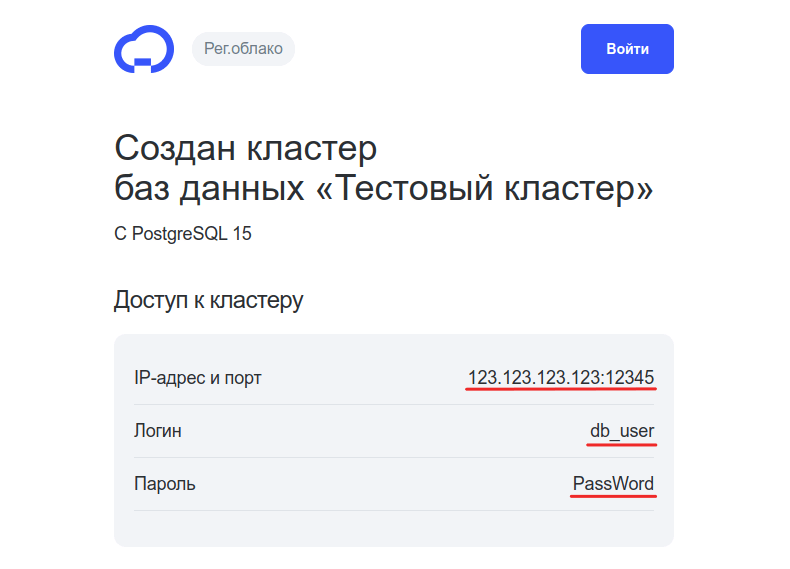
Подключенные реплики
Реплика — это копия фрагмента данных или базы целиком. При создании кластера облачной БД вы можете выбрать одну или несколько реплик, которые будут храниться на сервере.
В блоке «Подключенные реплики» указана следующая информация:
- количество реплик для заказанного кластера;
- IP-адрес, на котором размещена реплика;
- порт для подключения.
Как открыть информацию о кластере в личном кабинете
- 1 Перейдите в панель Рег.облака.
-
2
Откройте раздел Мои ресурсы и выберите Кластеры баз данных. Затем кликните по строке с названием нужного кластера:
Где найти пароль для доступа к серверу
Пароль для доступа к серверу можно найти только в стартовом письме — это сделано из соображений безопасности ваших данных.
Если вы случайно потеряли письмо, но не успели начать работу с базой данных, удалите кластер и создайте его заново, — тогда вы получите новое стартовое письмо.
Однако, если вы уже успели выполнить важные настройки БД, при утере пароля обратитесь в службу поддержки.
После этого перейдите на одну из вкладок. О содержимом каждой из них мы рассказали ниже.
Информация
Название этой вкладки полностью отражает содержание — здесь хранятся данные о количестве реплик и сервере их хранения, а также о главном сервере с кластером БД.
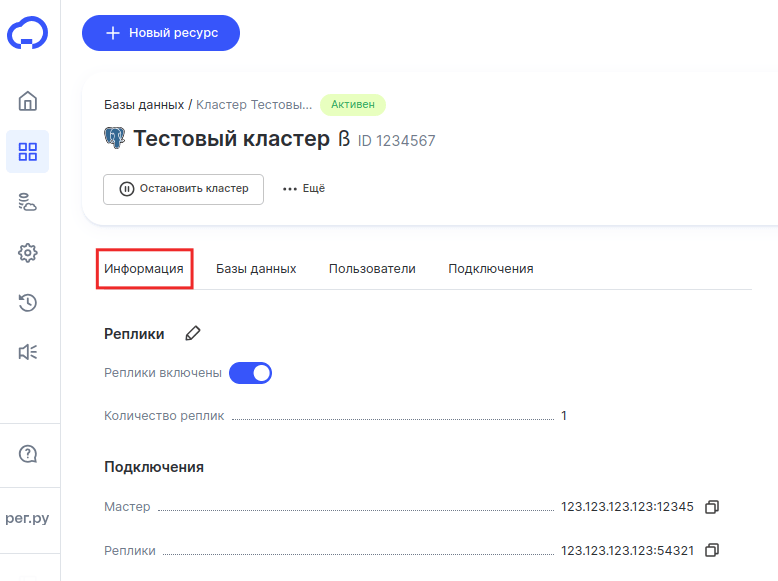
Помимо основного сервера и реплик во вкладке «Информация» размещена информация о количестве баз данных, числе пользователей и технических характеристиках кластера.
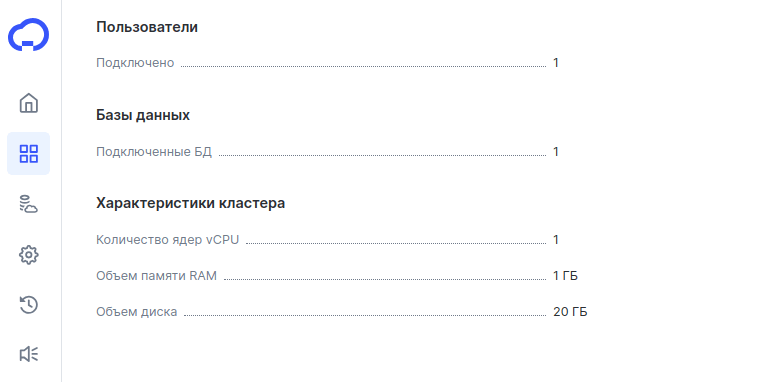
Базы данных
В этом блоке хранится информация о названиях баз данных, именах пользователей и адресах для подключения к СУБД.
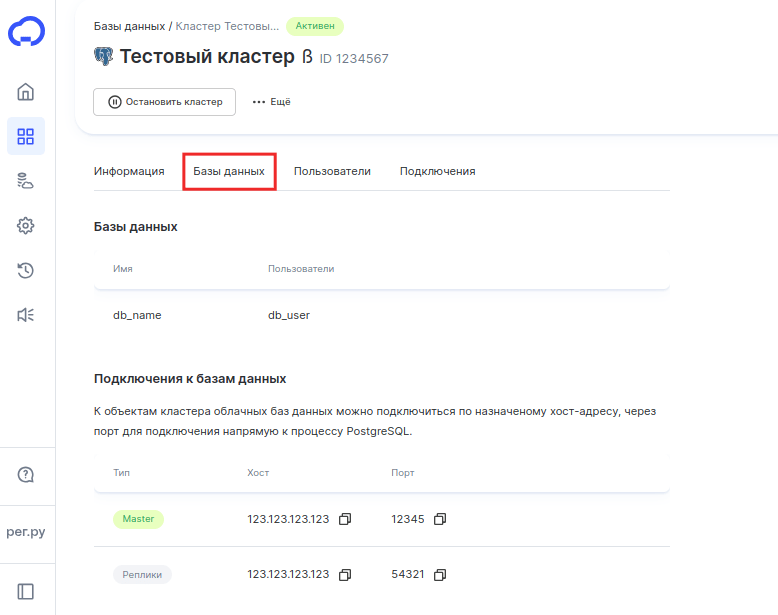
Пользователи
Во вкладке «Пользователи» хранится список всех пользователей и названия баз данных, с которыми они могут работать.
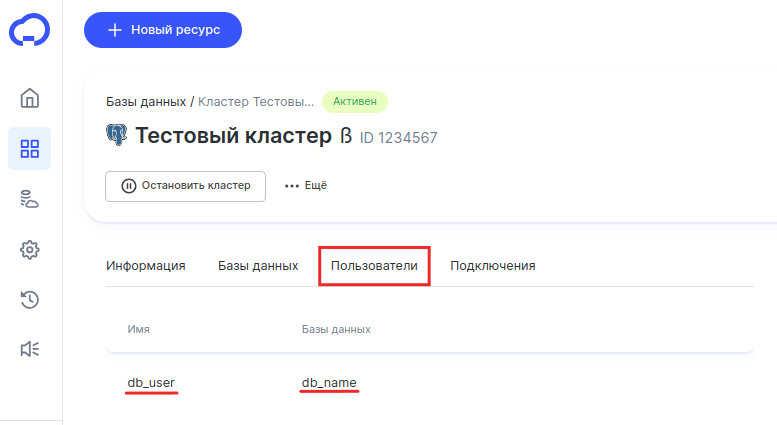
Подключения
Во вкладке «Подключения» вы можете найти основной IP и адреса серверов с репликами. Во втором столбце указан порт, который соответствует указанному IP-адресу.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊
Как управлять кластером облачной базы данных
В статье мы опишем основные действия, которые можно выполнить с кластером облачной базы данных.
Как остановить кластер
Если вы хотите взять паузу в работе над проектом, можно остановить кластер. В период остановки кластер будет недоступен, средства за ресурсы сервера БД списываться не будут.
Чтобы остановить кластер:
- 1 Перейдите в панель Рег.облака.
-
2
Откройте раздел Мои ресурсы и выберите Кластеры баз данных. Затем кликните по строке с названием нужного кластера:
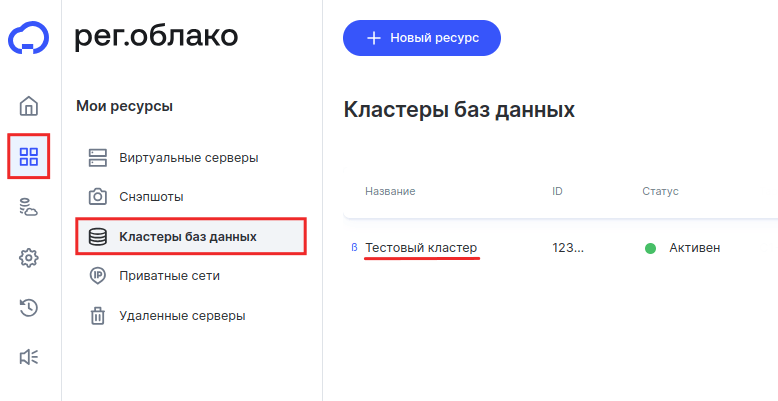
-
3
Нажмите Остановить кластер:
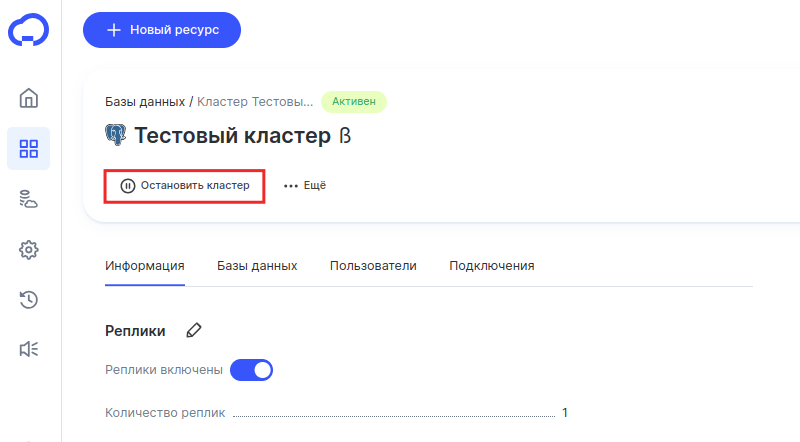
-
4
Подтвердите действие, нажав Остановить:
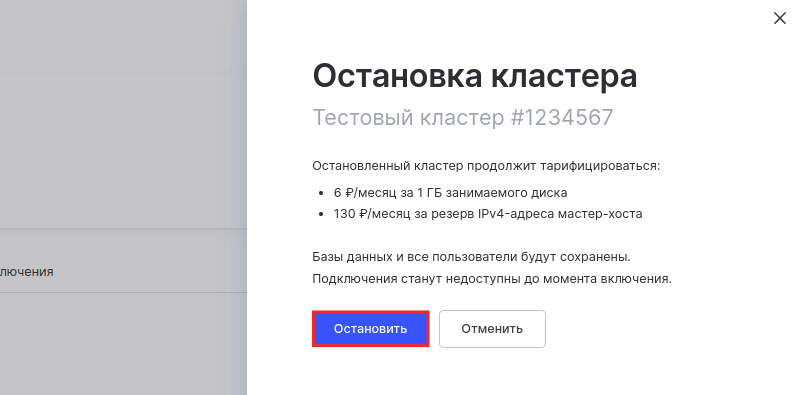
Готово, вы остановили работу кластера.
Как запустить кластер
Когда вы хотите возобновить работу над кластером, его нужно запустить повторно. Для этого:
- 1 Перейдите в панель Рег.облака.
-
2
Откройте раздел Мои ресурсы и выберите Кластеры баз данных. Затем кликните по строке с названием нужного кластера:
-
3
Нажмите Запустить сервер:
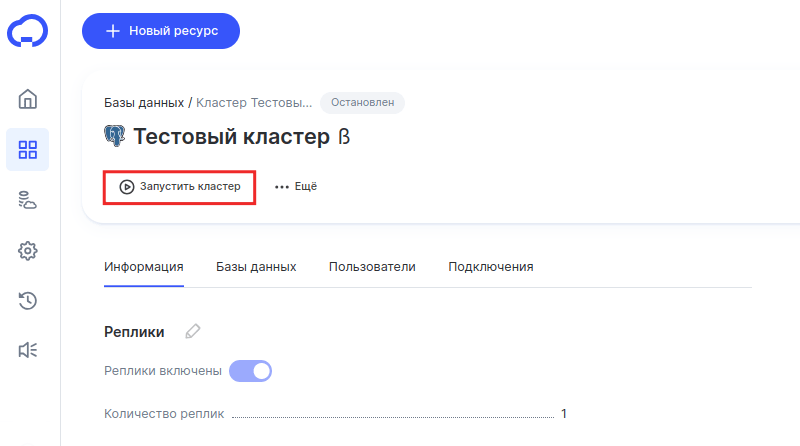
Готово, вы возобновили работу кластера.
Как переименовать кластер
При создании кластера БД вы можете использовать его стандартное название или назначить свое (в том числе и на кириллице). Однако, если вы опечатались при создании имени или хотите структурировать список в панели Рег.облака, можно переименовать кластер. Для этого:
- 1 Перейдите в панель Рег.облака.
-
2
Откройте раздел Мои ресурсы и выберите Кластеры баз данных. Затем кликните по строке с названием нужного кластера:
-
3
Нажмите Ещё и выберите Переименовать кластер:
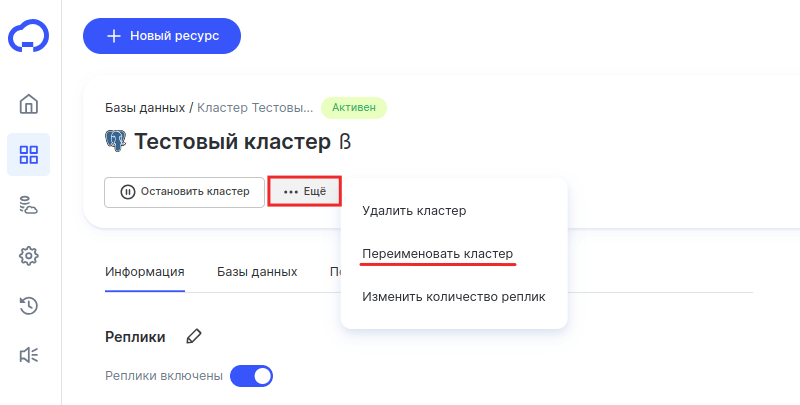
-
4
Укажите новое имя кластера. Затем кликните Переименовать:
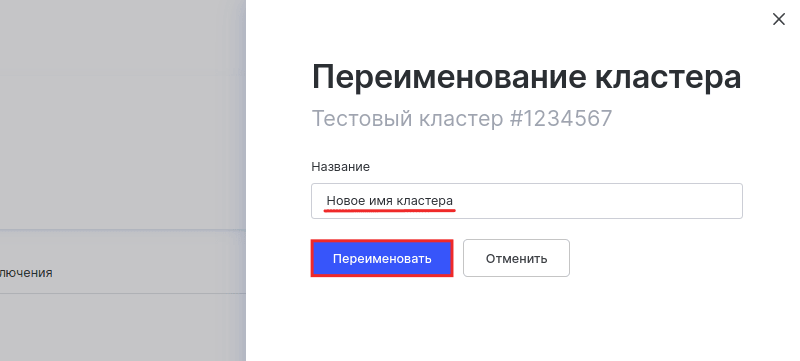
Готово, вы переименовали кластер.
Как удалить кластер
Если вы хотите окончательно закрыть проект или начать заново, кластер можно удалить. Для этого:
- 1 Перейдите в панель Рег.облака.
-
2
Откройте раздел Мои ресурсы и выберите Кластеры баз данных. Затем кликните по строке с названием нужного кластера:
-
3
Нажмите Ещё и выберите Удалить кластер:
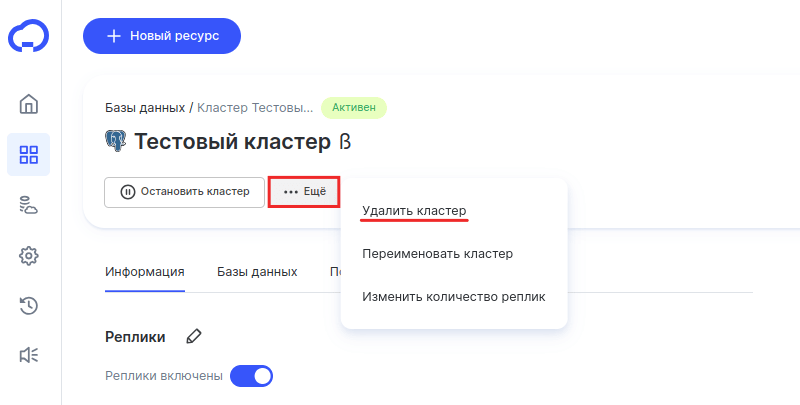
-
4
Подтвердите удаление. Для этого укажите текущее название кластера и кликните Удалить:
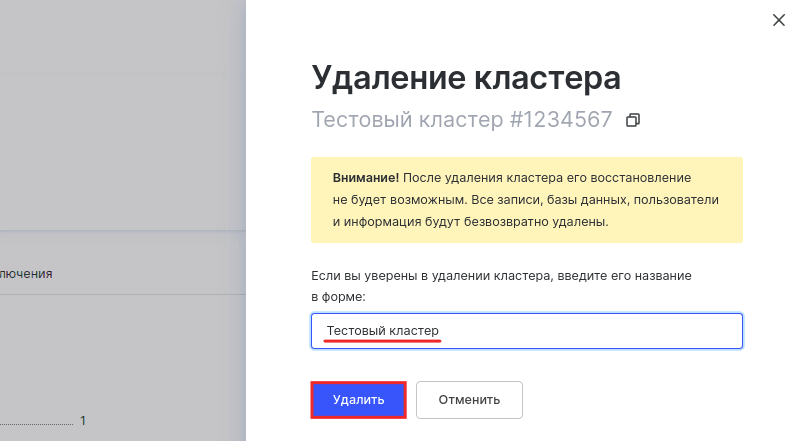
Готово, вы удалили кластер облачной базы данных.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊
Как создать кластер облачной базы данных
Как создать кластер баз данных
Чтобы создать кластер облачной базы данных:
- 1 Перейдите на страницу заказа услуги.
-
2
В блоке «Базовая СУБД» выберите нужную СУБД и ее версию:
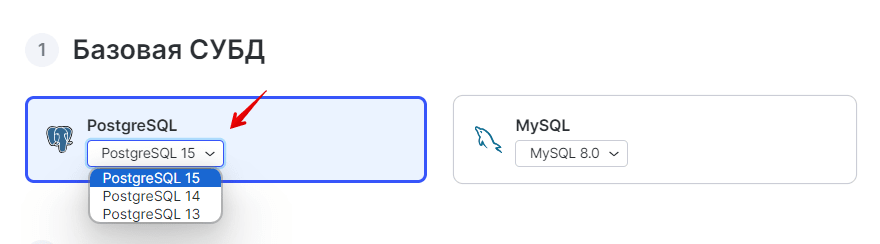
-
3
В блоке «Тарифы» выберите подходящий тариф:
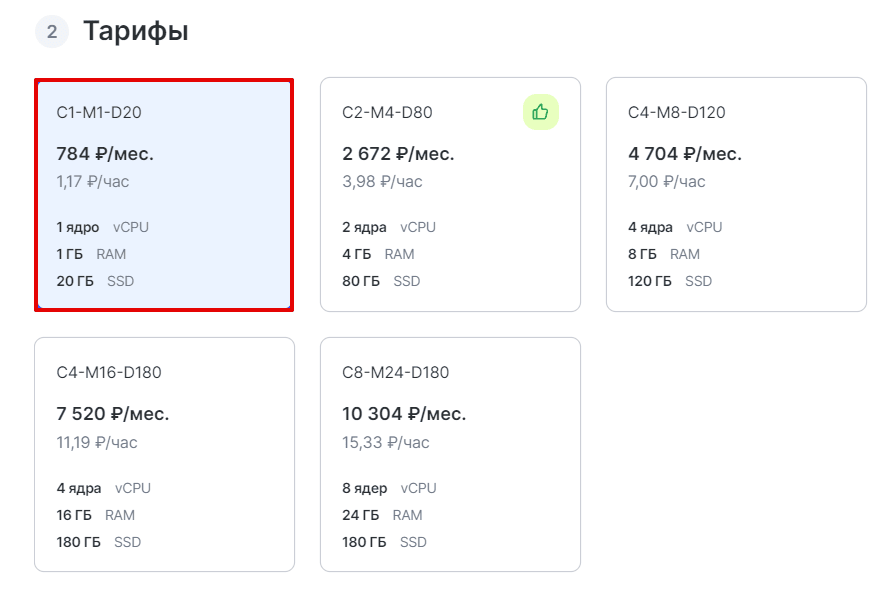
-
4
В блоке «Настройки кластера» укажите имя кластера:
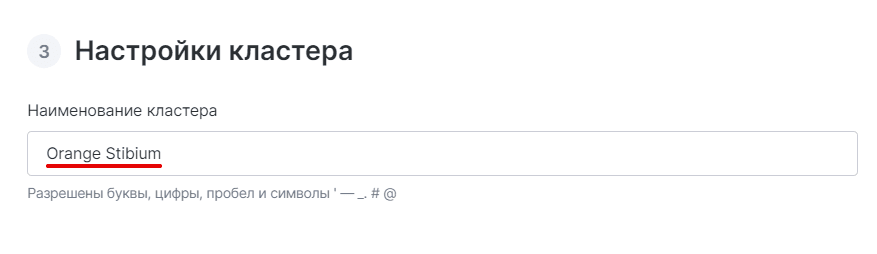
-
5
В блоке «Отказоустойчивость» при необходимости подключите систему репликации данных и выберите количество реплик:

-
6
В блоке «Базы данных» укажите наименование базы данных, имя пользователя и пароль:

-
7
Нажмите Создать кластер:
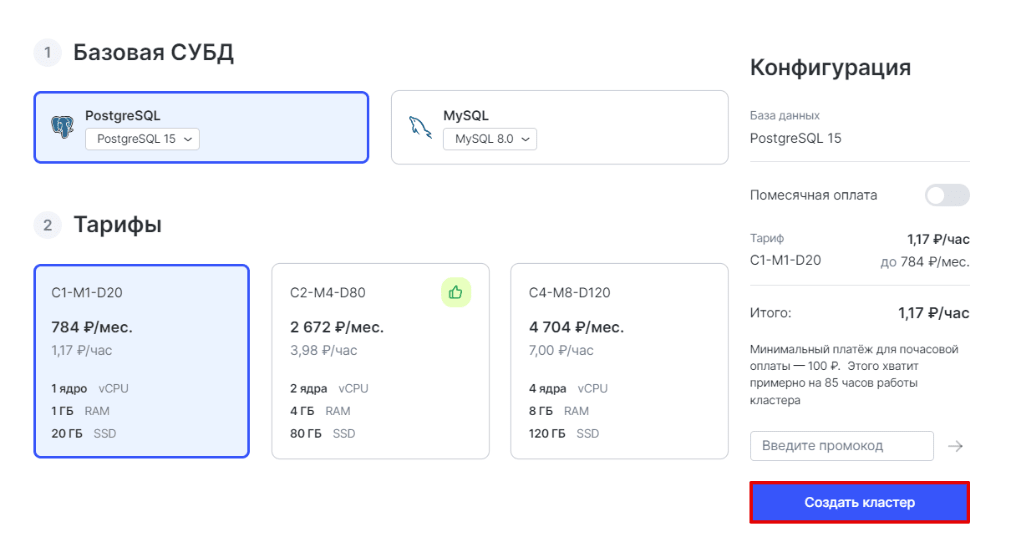
Если вы авторизованы, то автоматически попадете в панель управления. Если не авторизованы, войдите в личный кабинет или зарегистрируйтесь. После этого панель станет доступна в личном кабинете.
Готово, вы создали кластер баз данных.
Как передать кластер баз данных на другой аккаунт
Чтобы передать кластер баз данных на другой аккаунт, оставьте заявку в службу поддержки.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊
Управление репликами Облачной базы данных
В статье мы расскажем о том, как управлять репликами облачной базы данных.
Что такое репликация и как она работает
Репликация — это синхронизация информации в базах данных. Она реализуется путем копирования данных из одного места в другое, например, между двумя локальными хостами. Особенности работы репликации зависят от предустановленной СУБД.
В PostgreSQL репликация работает в режиме «master-slave». В этом случае master-сервер имеет права на чтение и запись, а slave-сервер — только на чтение.
Если речь идет о MySQL, то репликация выполняется в режиме multi-master. В этом режиме все серверы репликации равнозначны и обладают правами на чтение и запись.
Как перейти в панель управления облачными серверами
- 1 Перейдите в личный кабинет.
-
2
Откройте панель управления облачными серверами:
Как включить реплики
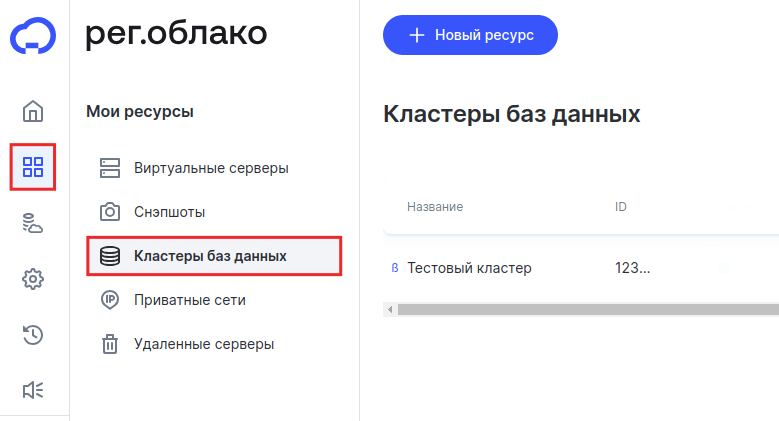
- 1 Авторизуйтесь в личном кабинете и перейдите в панель управления облачными серверами.
-
2
Выберите раздел Серверы — Кластеры баз данных:
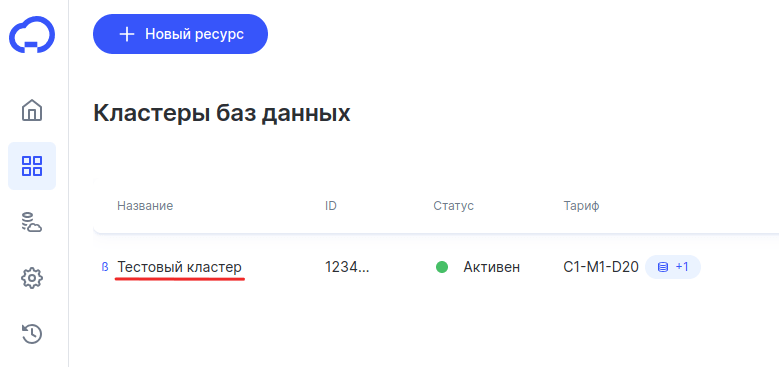
-
3
Кликните по строке с нужным кластером:
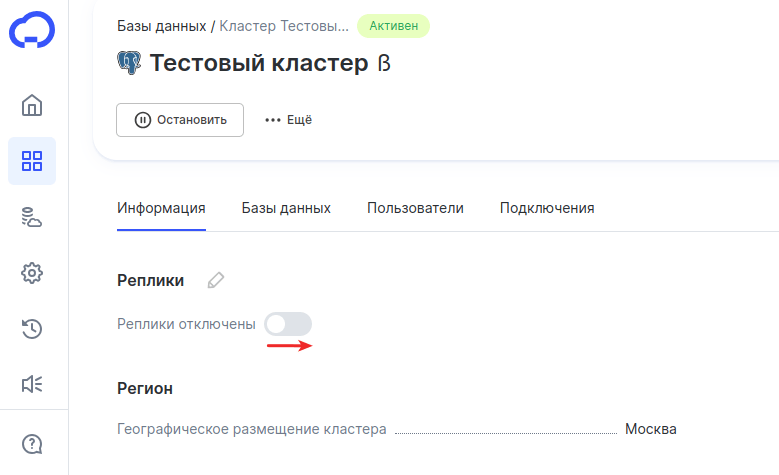
-
4
В блоке «Реплики» поставьте переключатель в положение ON:
-
5
Выберите количество реплик и нажмите Включить:
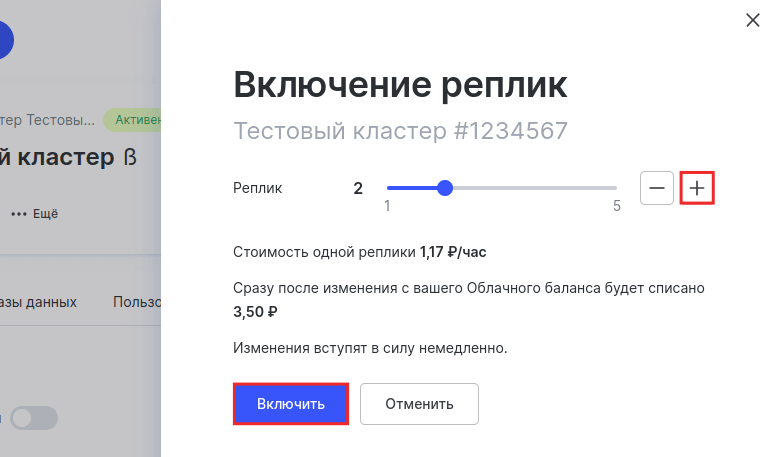
Готово, вы включили реплики.
Как изменить количество реплик
- 1 Авторизуйтесь в личном кабинете и перейдите в панель управления облачными серверами.
-
2
Выберите раздел Серверы — Кластеры баз данных:
-
3
Кликните по строке с нужным кластером:
-
4
В строке «Реплики» нажмите на карандаш:
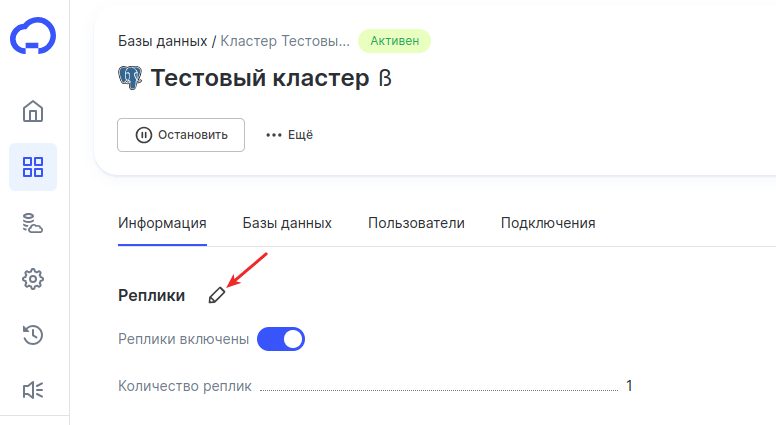
-
5
Добавьте нужное количество реплик и нажмите Изменить:
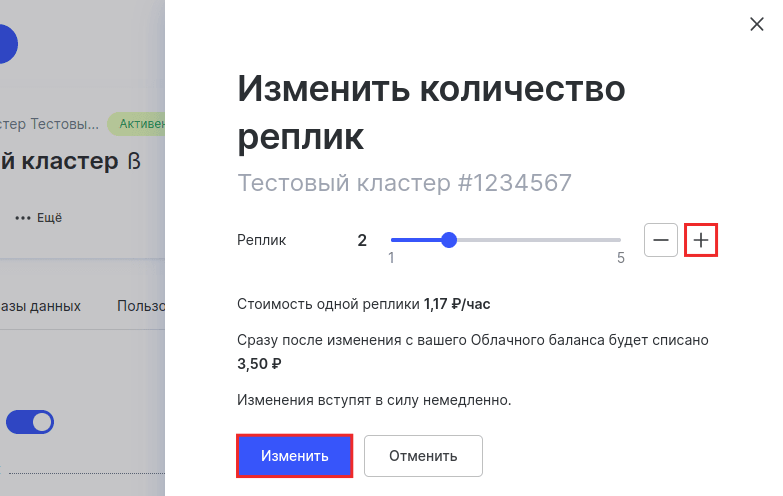
Если вам нужно уменьшить количество реплик, кликните по знаку минус и нажмите Изменить:
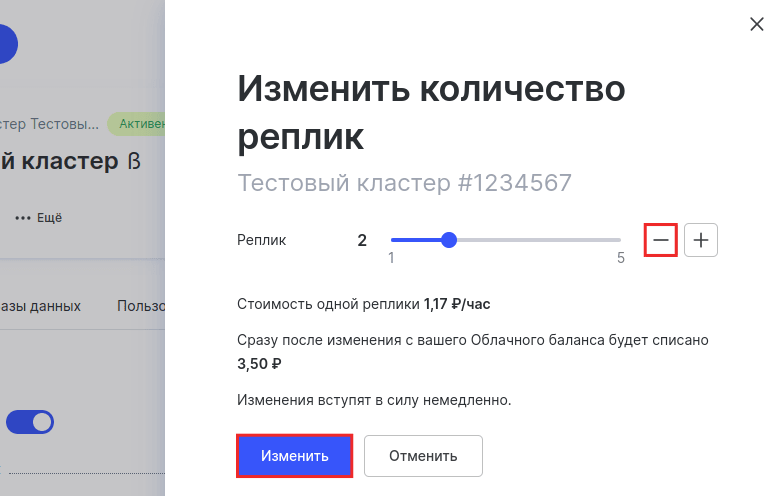
Готово, вы изменили количество реплик.
Как отключить реплики
- 1 Авторизуйтесь в личном кабинете и перейдите в панель управления облачными серверами.
-
2
Выберите раздел Серверы — Кластеры баз данных:
-
3
Кликните по строке с нужным кластером:
-
4
В блоке «Реплики» поставьте переключатель в положение OFF:
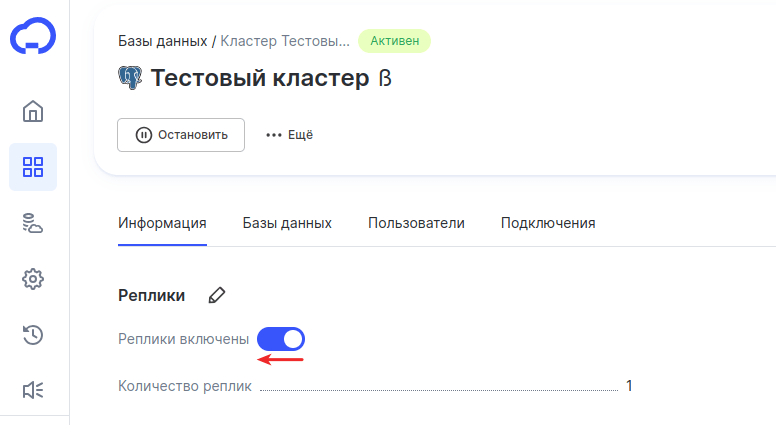
-
5
По необходимости отметьте пункт Оставить одну резервную реплику и нажмите Отключить:
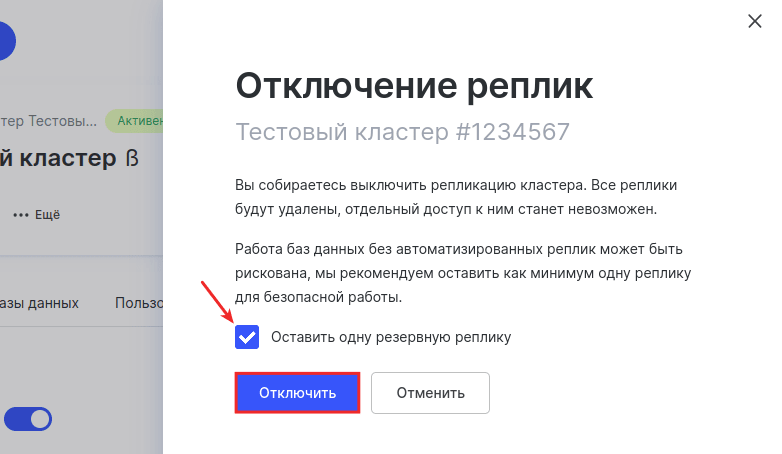
Готово, вы отключили реплики.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊
Как изменить тариф кластера баз данных
В этой статье мы расскажем, как повысить или понизить тариф кластера баз данных.
При смене тарифного плана изменяются параметры кластера: дисковое пространство, CPU, память. При этом все данные и IP-адрес вашего кластера будут сохранены. Во время изменения тарифа ваш кластер будет остановлен и запущен уже с новыми параметрами.
Обратите внимание
- При смене тарифного плана учитывайте, что на целевом тарифе размер дискового пространства должен быть больше или равен текущему. Перейти на тариф с меньшим диском невозможно;
- вернуться на старый тарифный план можно только в том случае, если при смене тарифа размер дискового пространства не увеличивался;
- при смене тарифа виртуальный диск может быть перенесен на другую физическую ноду. В этом случае кластер будет недоступен несколько минут, в среднем за минуту будет передано 3 ГБ данных.
Чтобы изменить тариф кластера баз данных:
-
1
Авторизуйтесь в личном кабинете и перейдите в раздел Рег.облако:
-
2
Выберите раздел Кластеры баз данных:
-
3
Напротив нужного кластера кликните на 3 точки и нажмите Изменить тариф:
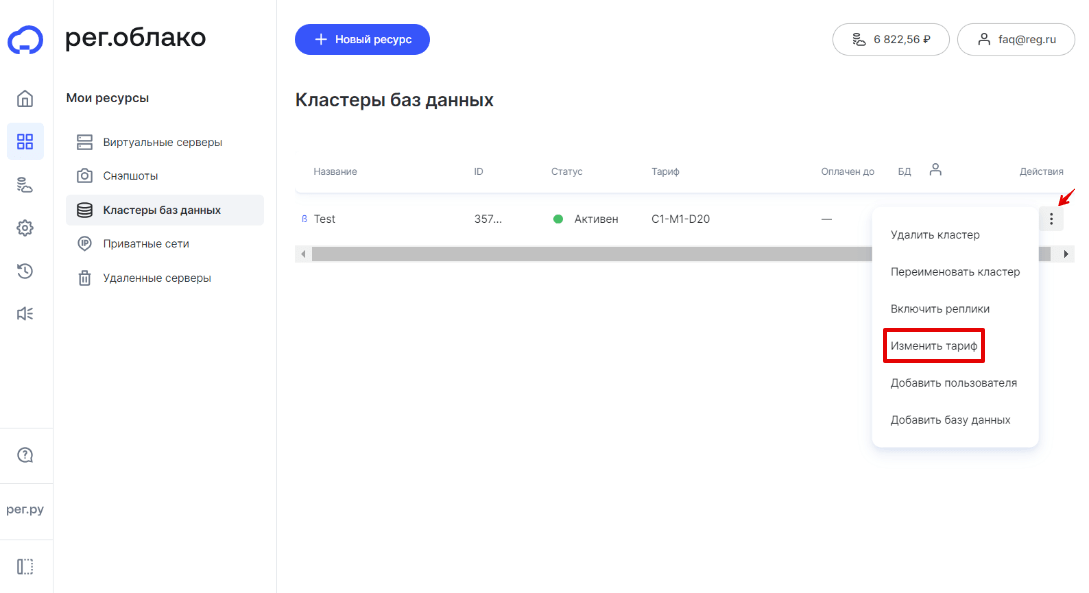
-
4
В открывшейся шторке выберите подходящий тариф и нажмите Изменить тариф:
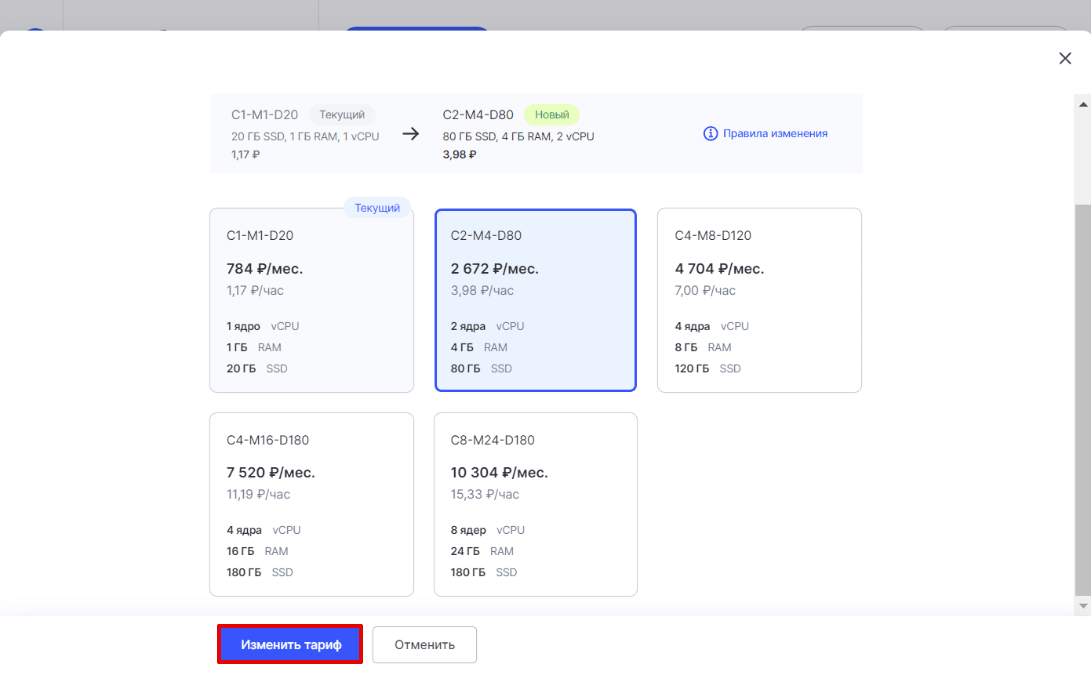
Готово, вы изменили тарифный план сервера.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊
Реляционные базы данных
В этой статье расскажем, что такое реляционные базы данных, приведем примеры нереляционных и реляционных баз данных. Для начала дадим определение базам данных и СУБД.
База данных (БД) — упорядоченный набор данных. Она используется для хранения информации об объектах и связях между ними. Например, база данных интернет-магазина может хранить в себе информацию о клиентах, продуктах и заказах.
Для управления базой данных существует специальное программное обеспечение — СУБД (система управления базами данных). СУБД предоставляет пользователю средства для создания, обновления, удаления и запроса данных из базы. Более подробно СУБД описаны в статье.
Существует несколько типов баз данных:
реляционные,
иерархические,
сетевые,
объектно-ориентированные,
NoSQL или нереляционные.
Популярные реляционные базы данных: MySQL, PostgreSQL, Microsoft SQL Server, Oracle и SQLite.
Что такое реляционная база данных
Реляционная база данных (РБД) — это тип базы данных, основанный на реляционной модели данных.
Реляционная модель данных — способ организации данных с использованием таблиц. Таблицы формируют отношения между данными, и в контексте РБД термины «таблицы» и «отношения» используются как синонимы. В реляционной модели с помощью таблиц данные представляются в удобной и структурированной форме для хранения, доступа и управления. Каждая таблица — отдельный объект, каждая строка в таблице (или кортеж) соответствует конкретной записи или экземпляру этого типа, а столбцы (или атрибуты) определяют характеристики этой сущности.
Например, в таблице с товарами интернет-магазина кортежи могут иметь такие атрибуты, как название, дата_производства, цена и т. д.
Для определения записей, которые могут вноситься в столбец, при его создании указывается тип данных.
Распространенные типы данных:
даты,
строки,
целые числа,
логические значения.
Особенности и ключевые характеристики реляционных баз данных:
- 1. Организация данных в виде таблиц. Каждая из них — отдельная сущность.
- 2. Доступ к данным осуществляется с помощью языка запросов — SQL. SQL позволяет выполнять операции чтения, записи, обновления и удаления данных в таблицах.
- 3. Целостность данных. Данные в базе соответствуют заданной структуре.
- 4. Независимость данных и приложений. Вы можете изменять структуру базы данных без изменения приложений, которые используют эти данные.
- 5. Поддержка многопользовательского доступа. Механизмы блокировки транзакций обеспечивают согласованный доступ к данным и предотвращают конфликты и потерю данных.
-
6.
Гибкость. С помощью отношений и связей между таблицами можно гибко моделировать данные.
- 7. Расширяемость. По мере необходимости можно добавлять новые таблицы, столбцы и индексы.
Связи между данными в разных таблицах устанавливаются с помощью ключей.
Первичный ключ (Primary Key)
Каждая таблица содержит как минимум один столбец, поля которого могут использоваться как уникальные идентификаторы записи. Этот столбец называется первичным ключом. Первичный ключ обеспечивает быстрый доступ к записям и определяется при создании таблицы (он может быть указан с использованием специального ключевого слова, например, в SQL это PRIMARY KEY). Значение ключа всегда уникально и не может быть пустым (Null).
Внешний ключ (Foreign Key)
Столбец или набор столбцов в таблице, поля которого ссылаются на первичный ключ, называется внешним или вторичным ключом. Он создает связи между таблицами и обеспечивает целостность данных. Вторичный ключ не всегда уникален (в таблице может быть несколько записей с одинаковыми значениями вторичного ключа). Также значения могут быть пустыми (NULL), например, если связанные записи отсутствуют. Определить вторичный ключ можно с помощью ограничений (в SQL это FOREING KEY), что обеспечит правильное сопоставление вторичного ключа с первичным.

ACID
Последовательность операций в базе данных, которые выполняются как единое целое, называется транзакцией. Для гарантии надежности транзакции существуют стандартные наборы свойств.
ACID — модель транзакций, которая используется в реляционных базах данных наиболее часто. Ее название — это аббревиатура от слов Atomicity, Consistency, Isolation, Durability. Это означает:
Atomicity (Атомарность) — свойство, которое не допускает состояния, когда одна часть операции завершается успешно, а другая – нет. Если хотя бы одна операция в транзакции не может быть выполнена, то все изменения, сделанные до этого момента, отменяются (производится откат). Например, в транзакции, которая включает две операции – перевод средств со счета и начисление комиссии, – неначисление комиссии нарушает атомарность.
Consistency (Согласованность) — свойство, при котором выполнение транзакции не нарушает целостность данных. Другими словами, если транзакция завершается успешно, изменения, которые она вносит, сохраняются в базе. Например, когда вы покупаете товар в интернет-магазине, после успешной транзакции количество товаров в наличии уменьшается. Если транзакция отменяется – происходит откат к изначальному состоянию и количество товаров в наличии остается прежним.
Isolation (Изоляция) — свойство, которое гарантирует изолированное выполнение транзакций. Например, в онлайн-системе бронирования билетов изоляция предотвратит возможный конфликт выполнения транзакции, если несколько пользователей будут пытаться одновременно забронировать билеты на одно и то же мероприятие. Если один пользователь забронировал определенные места, они не станут недоступными для других пользователей до момента подтверждения бронирования или отмены транзакции первого пользователя.
Durability (Долговечность или надежность) — это свойство гарантирует сохранение всех успешных транзакций в базе данных даже в случае сбоя системы. Например, после оплаты заказа в интернет-магазине статус заказа меняется на «Оплачено». Если после этого происходит сбой системы или отключение питания, после восстановления работоспособности системы заказ останется в этом же статусе, данные о платеже не потеряются.
Зачем нужна реляционная база данных
Благодаря своей гибкости, надежности и возможности эффективно работать со структурированными данными, реляционные базы данных остаются самыми популярными и используются для многих задач.
Где можно найти применение реляционным БД:
Системы управления клиентскими данными хранят информацию о клиентах, их контактных данных, покупках, предпочтениях.
Финансовые системы используют РБД для учета транзакций, управления клиентскими счетами, анализа рисков.
Системы управления персоналом с помощью РБД хранят информацию о сотрудниках, их зарплате и рабочих часах.
Системы управления образованием используют базы данных для хранения информации о студентах, расписаниях занятий, учебных планах и оценках.
Медицинские информационные системы используют РБД для управления медицинскими процессами: записи пациентов, результатов анализов и т. д.
Преимущества и перспективы реляционных баз данных
Реляционная модель данных имеет ряд достоинств:
- 1. Простота. Данные представлены в виде таблиц и имеют четко определенные связи между друг другом. Это облегчает организацию информации.
- 2. Целостность данных. Поддержка ACID-свойств гарантирует надежность транзакций, обеспечивает целостность данных и снижает риск их потери. Другие типы баз данных не могут одновременно поддерживать целостность больших объемов данных. Например, NoSQL обеспечивает только окончательную целостность – это основное отличие реляционной базы данных от нереляционной.
- 3. Независимость данных и приложений. Изменение структуры базы данных может происходить без изменений в приложениях, которые используют эти данные.
- 4. Многопользовательский доступ. Поддержка многопользовательского доступа. Механизмы блокировки и транзакций обеспечивают согласованный доступ к данным и предотвращают конфликты и потерю данных.
- 5. Разнообразие систем управления базами данных (СУБД), поддерживающих реляционные модели данных.
У реляционных баз данных есть будущее в виде автономных систем, которые будут способны функционировать без человеческого вмешательства. Разработка автономных РБД — актуальное направление исследований в области баз данных.
Для расширения возможностей реляционной модели многие провайдеры переходят на облачные базы данных. Облачные базы данных включают в себя некоторые функциональности, которые приближают их к концепту автономных баз данных.
Что предлагает Рег.облако
Рег.ру предлагает готовое решение на основе Рег.облака, которое предназначено для работы с базами данных PostgreSQL и MySQL в облаке.
Система управления базами данных предустановлена в кластере. Вы можете использовать облачную базу данных для любых целей, например, для разработки приложений, тестирования или мониторинга систем.
Преимущества облачных баз данных:
полностью готовый сервер. Перед началом работы достаточно выбрать только версию СУБД и количество реплик;
тарифы с разными характеристиками, которые подойдут для любого проекта;
база данных готова к работе сразу после заказа;
облачные БД могут быть масштабированы горизонтально и вертикально для увеличения вычислительной мощности и производительности;
предусмотрена автоматическая репликация. Реплики повысят отказоустойчивость вашего кластера;
облачная структура позволяет хранить конфиденциальные данные.
PostgreSQL
PostgreSQL (или Postgres) — это объектно-реляционная система управления базами данных с открытым исходным кодом. Postgres включает в себя поддержку SQL, транзакционную целостность и возможность расширения с помощью дополнительных модулей и плагинов.
PostgreSQL, кроме обработки стандартных типов данных, может быть использован для хранения данных в качестве объектов со свойствами.
Подобрать подходящее решение для PostgreSQL в облаке вы можете на странице.
MySQL
MySQL — самая популярная СУБД. Она предоставляет полноценную поддержку стандарта SQL и широкий набор функциональных возможностей: транзакционную целостность, управление пользователями и доступом, репликацию данных, поддержку хранимых процедур, триггеров и представлений. Ключевая особенность — высокая производительность и масштабируемость.
Заказать MySQL в облаке вы можете на странице.
Какой стек технологий используется для Облачных баз данных
Для реализации MySQL и PostgreSQL в облаке используются:
— OpenStack для создания облачного хранилища данных,
— Kubernetes для автоматизации работы с контейнерами облака,
— KVM в качестве технологии виртуализации.
Также вы можете перенести базы данных с любого вида хостинга. Для этого используйте инструкцию.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊
Основные команды SQL
В этой статье разберемся, что такое SQL и как работают основные SQL-запросы.
Что такое SQL
SQL (Structured Query Language) — язык структурированных запросов. Он предназначен для управления реляционными базами данных в СУБД, таких как PostgreSQL, MySQL, Oracle и Microsoft SQL Server. Что такое реляционные базы данных, мы рассказали в статье. С помощью SQL можно добавлять, удалять, изменять и извлекать данные из базы данных. Также язык позволяет описывать данные и их структуру, взаимодействовать с другими языками через библиотеки и модули SQL и устанавливать разрешения на доступ к данным.
SQL — наиболее распространенный язык программирования в области работы с БД.
— Он используется для:
— веб-разработки,
— бизнес-аналитики,
— администрирования баз данных,
— обработки данных.
Виды SQL команд
Существует несколько видов SQL-команд.
Data Definition Language (DDL), или язык определения данных — это группа операторов для определения структуры БД и работы с объектами этой базы. DDL включает в себя следующие команды:
-
1
CREATE. Команда для создания новых объектов базы данных, например, таблиц, индексов или представлений. Создадим с помощью этой команды таблицу:
CREATE TABLE TableName;Вместо TableName укажите название таблицы.
-
2
ALTER. Команда, с помощью которой можно изменять структуру существующих объектов базы данных, например, добавлять или удалять столбцы в таблице. Добавим в созданную таблицу столбец, который будет хранить числовые значения:
ALTER TABLE TableName ADD COLUMN column INT;Где:
— TableName — название таблицы;
— column — название столбца.
-
3
DROP. Команда для удаления объектов базы данных. Удалим таблицу с помощью этой команды:
DROP TABLE TableName;Вместо TableName укажите название таблицы.
Data Manipulation Language (DML), или язык манипуляций с данными. Это команды для управления данными. DML включает в себя:
-
1
SELECT. Команда для извлечения данных из БД. Извлечем все данные из таблицы:
SELECT * FROM TableName;Вместо TableName укажите название таблицы.
-
2
INSERT. Вставляет новые записи в таблицу. Предположим, у нас есть таблица с наименованиями и стоимостью товаров, добавим в нее запись:
INSERT INTO Products (id, name, price) VALUES (1, 'bread', 30);Где:
— id — уникальный идентификатор товара;
— name — название товара в строковом формате;
— price — цена товара в числовом формате.
-
3
UPDATE. Обновляет и изменяет существующие записи в таблице. Например, изменим стоимость товара в таблице с id равным '1':
UPDATE Products SET price = 35 WHERE id = 1; -
4
DELETE. Удаляет записи из таблицы. Команда DELETE удалит все строки в таблице, если не указано других условий. Удалим товар с идентификатором равным '1' из таблицы Products:
DELETE FROM Products WHERE id = 1;
Data Control Language (DCL), или язык контроля данных — группа операторов для управления правами доступа к данным в БД. Администраторы баз данных могут устанавливать различные уровни доступа для пользователей или ролей для обеспечения безопасности и защиты данных. DCL-команды:
-
1
GRANT. Команда для предоставления различных прав доступа к объектам базы данных другим пользователям. Откроем доступ к таблице:
GRANT ALL PRIVILEGES ON Products TO user;Где:
— Products — название таблицы, к которой вы хотите предоставить доступ;
— user — пользователь, которому эти права выдаются.
-
2
REVOKE. Команда отзывает предоставленные к объектам права. Например:
REVOKE ALL PRIVILEGES ON Products TO user;Где:
— Products — название таблицы, доступ к которой необходимо ограничить;
— user — пользователь, у которого отзываются права.
Transaction Control Language (TCL), или язык управления транзакциями — группа операторов, управляющих транзакциями в базе данных. SQL команды транзакции:
-
1.
COMMIT. Фиксирует изменения, сделанные в транзакции, сохраняет их в БД. После выполнения команды изменения необратимы.
-
2.
ROLLBACK. Отменяет изменения, сделанные в текущей транзакции.
-
3.
SAVEPOINT. Создает точки сохранения внутри транзакции. При необходимости поможет сделать откат до определенного состояния.
Правила написания запросов
При написании SQL-запросов необходимо следовать следующим правилам:
-
1
SQL не чувствителен к регистру, например, SELECT можно написать как в верхнем, так и в нижнем регистре. Однако писать ключевые слова принято в верхнем регистре, а имена таблиц и столбцов в нижнем. Также имена таблиц и столбцов в запросах нужно писать в точности так, как они были названы изначально. Например, если таблица называется Products, а в запросе написать products, запрос выполнится некорректно.
-
2
Оставлять комментарии можно несколькими способами. Многострочные комментарии будут начинаться с '/*' и заканчиваться '*/'. Однострочные комментарии будут писаться с двойного дефиса (--). Например:
/* Это многострочный комментарий */ CREATE DATABASE Name; -- Это однострочный комментарий CREATE DATABASE Name; -- Это тоже однострочный комментарий -
3
Если имя таблицы, столбца или значение содержит пробелы или специальные символы, оно должно быть заключено в кавычки (« »). Строковые значения заключаются в одинарные кавычки ('). Например:
-- Создание таблицы с именем, содержащим пробелы CREATE TABLE "my table"; -- Вставка строки INSERT INTO my_table (column) VALUES ('строка'); - 4 Каждый SQL запрос должен завершаться точкой с запятой (;).
-
5
Для экранирования специальных символов внутри строк используется обратный слеш (\). Например, если мы ищем строчку с цитатой, запрос будет выглядеть так:
SELECT * FROM Quotes WHERE contents LIKE 'Plato is said to once have said \"Lorem ipsum dolor sit amet\".'; - 6 Числа вносятся в таблицы без кавычек.
- 7 Пробелы и отступы игнорируются в SQL-запросах. Однако их стоит использовать, чтобы запросы имели читабельный вид.
Основные команды SQL
SELECT, INSERT, UPDATE, DELETE, CREATE, ALTER, DROP — это основные команды SQL.
Рассмотрим синтаксис некоторых из них. Для примера воспользуемся данными из таблицы Employees со списком сотрудников компании.
SELECT
Команда SELECT может использоваться со следующими ключевыми словами:
— DISTINCT — выбирает уникальные значения из столбцов, устраняя повторения.
— ALL — возвращает все данные из таблицы.
— FROM — указывает на таблицу из которой извлекаются данные.
— WHERE — устанавливает фильтрацию.
— GROUP BY — устанавливает правила группировки данных.
— HAVING — устанавливает правила фильтрации сгруппированных записей.
— ORDER BY — сортирует данные по возрастанию или убыванию.
— LIMIT — задает количество записей, которые необходимо получить из результата запроса.
Обязательными элементами запроса SELECT являются только SELECT и FROM.
С помощью следующей команды извлечем имена сотрудников из таблицы, чей возраст старше 30, отсортируем результаты по убыванию возраста и вернем только первые 2 записи:
SELECT name
FROM Employees
WHERE age > 30
ORDER BY age DESC
LIMIT 2;INSERT
Команда INSERT в SQL состоит из двух ключевых слов:
— INSERT INTO — указывает на таблицу, в которую нужно добавить данные.
— VALUES — указывает значения, которые вставляются в таблицу. Указать значения можно списком, который соответствует порядку столбцов в таблице, или через подзапрос.
Добавим в таблицу Employees нового сотрудника. Сделать это можно двумя способами:
-- Простая вставка значений в таблицу с указанием столбцов
INSERT INTO Employees (name, age, salary)
VALUES ('Leon', 30, 18);
-- Вставка значений в таблицу без указания столбцов (все столбцы)
INSERT INTO Employees
VALUES ('Andrey', 25, 150, gym);UPDATE
Ключевые слова запроса UPDATE:
— SET — определяет столбцы и значения для обновления.
— WHERE — задает условие для определения записей, которые нужно обновить. Если условия нет, обновляются все строки в таблице.
Команда UPDATE для изменения зарплаты сотрудников в таблице Employees, у которых в хобби указан gym, будет выглядеть так:
UPDATE Employees
SET salary = 100
WHERE hobby = 'gym';DELETE
Запрос будет состоять из следующих ключевых слов:
— DELETE FROM — указывает на таблицу, из которой необходимо удалить данные.
— WHERE — определяет, какие строки из таблицы нужно удалить. Если не указать условие, будут удалены все строки таблицы.
Удалим из таблицы Employees сотрудников, чей возраст меньше 30:
DELETE FROM Employees
WHERE age < 30;Ограничения целостности в базах данных
Для обеспечения надежности и целостности данных в соответствии с принципами ACID в базах данных вводятся определенные правила — ограничения целостности (integrity constraints). Они определяют допустимые значения и структуру данных в БД. Это помогает предотвратить ошибочные операции.
Ниже описаны некоторые ограничения целостности в БД с примерами.
Первичный ключ (Primary Key Constraint)
Первичный ключ гарантирует уникальность в столбце или группе столбцов. Например, в таблице Employees каждый id должен быть уникальным.
/* Создание таблицы Employees с первичным ключом на столбце id.
Где:
— id — уникальный идентификатор для сотрудников,
— name — столбец столбец с именами сотрудников с типом данных строка длиной до 50 символов. */
CREATE TABLE Employees (
id INT PRIMARY KEY,
name VARCHAR(50)
);Ограничение NOT NULL
Ограничение NOT NULL требует, чтобы столбец не содержал значения NULL, то есть не был пустым. Например, столбец name в таблице Employees не может быть пустым.
-- Создание таблицы Employees с ограничением NOT NULL в столбце name.
CREATE TABLE Employees (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL
);Ограничение на уникальность (Unique Constraint)
Ограничение на уникальность предотвращает дублирование информации. Например:
-- Создание таблицы Products с ограничением на уникальность в столбце product_code.
CREATE TABLE Products (
product_id INT PRIMARY KEY,
product_code VARCHAR(50) UNIQUE,
product_name VARCHAR(100)
);Попытка вставить или обновить запись с уже существующим значением в столбце product_code приведет к ошибке.
При попытке нарушения целостности система может среагировать несколькими способами:
- 1 Откат. Состояние БД восстановится до состояния, зарегистрированного в журнале на момент начала транзакции.
- 2 Компенсирующие действия. Например, выполнится альтернативная операция, которая не нарушит целостность данных.
- 3 Игнорирование. Попытка нарушения целостности будет проигнорирована, и система продолжит выполнение операции.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊
Ограничения SQL: как создать, примеры
Для обеспечения целостности базы данных (соответствия заданной структуре) в SQL используются ограничения, которые помогают предотвращать некорректные операции. В статье разберемся, что такое ограничения, рассмотрим их виды и способы создания.
Что такое ограничения SQL
Ограничения (constraint) — это правила, которые накладываются на данные в таблицах. Они определяют условия, которым должны соответствовать данные при вставке, обновлении или удалении полей в таблице.
Например, мы храним данные о сотрудниках в таблице Employees, и нам нужно не допустить сохранения отрицательных значений в столбце с возрастом. С помощью ограничения CHECK мы можем задать условие «Age > 0», и все вводимые данные, не соответствующие этому условию, не будут сохранены.
Типы ограничений в SQL
Есть два вида ограничений: ограничения целостности данных и ограничения целостности ссылок.
Ограничения ссылочной целостности обеспечивают целостность ссылок между связанными таблицами. К ним относится FOREIGN KEY constraint, или ограничение внешнего ключа. Оно гарантирует, что значения в столбцах одной таблицы ссылаются на существующие значения в другой таблице.
Ограничения целостности (integrity constraints) определяют отношения между данными в разных таблицах и обеспечивают согласованность данных в соответствии с установленными правилами.
К целостным ограничениям относятся:
— Ограничение NOT NULL. Гарантирует отсутствие пустых значений (NULL) в столбце.
— UNIQUE — ограничение, которое гарантирует уникальность значений.
— PRIMARY KEY constraint (ограничение первичного ключа). Уникально идентифицирует каждую запись в таблице.
Ограничения целостности классифицируются по области действия, способам реализации и времени проверки.
Ограничения целостности по области действия
- 1 Domain Constraints, или ограничения домена. Они устанавливают ограничения и допустимые значения в SQL на определенные типы данных (домены). Например, когда возраст сотрудников компании не может быть меньше 18 и больше 65.
- 2 Attribute Constraints, или ограничения атрибута (столбца). Они определяют условия, которым должны соответствовать значения в определенном столбце. Например, в таблице «Товары» значения в столбце «Цена» не могут быть отрицательными.
- 3 Tuple Constraints, или ограничения кортежа (строки). Они определяют условия, которые должны выполняться для каждой строки в таблице. Например, когда нам нужно, чтобы возраст сотрудников был в диапазоне от 18 до 65, мы можем использовать ограничение CHECK для проверки соответствия этому условию.
Ограничения целостности по способам реализации
- 1 Declarative Constraints, или декларативные ограничения. Эти ограничения определяются при создании таблиц sql и объявляются вместе со схемой базы данных с помощью языка определения данных. К ним относятся ограничение UNIQUE и CHECK, NOT NULL, PRIMARY KEY и FOREIGN KEY.
- 2 Procedural Constraints, или процедурные ограничения. Эти ограничения реализуются с использованием хранимых процедур, триггеров и других программных объектов в базе данных. Процедурные ограничения используются для сложных условий, которые нельзя выразить с помощью декларативных ограничений.
Ограничения целостности по времени проверки
Ограничения по времени проверки определяются на уровне всей базы данных и указывают, когда и каким образом должны быть выполнены проверки целостности данных. Часть из них проверяется немедленно в момент выполнения операции, у других проверка отложена до момента завершения транзакции.
Добавление ограничений SQL
Рассмотрим способы создания ограничений в базах данных.
Ограничение Not Null
NOT NULL гарантирует, что в столбце таблицы не будет значений NULL. То есть при вставке новой или обновлении существующей строки столбец, для которого установлено ограничение, не должен остаться пустым.
Предположим, нам нужно создать таблицу Employees со столбцами EmployeeID, FirstName, LastName, Age и Email. Используем ограничение NOT NULL, чтобы не допустить пустых значений в столбцах FirstName, LastName, Age и Email. Команда будет выглядеть следующим образом:
/* Создание таблицы Employees
Где:
— EmployeeID — уникальный идентификатор сотрудника,
— FirstName — столбец с типом данных «строка» (ячейка объемом до 50 символов), который будет хранить имена сотрудников,
— LastName — столбец с типом данных «строка» (ячейка объемом до 50 символов), который будет хранить фамилии сотрудников,
— Email — столбец с типом данных «строка» (ячейка объемом до 100 символов), который хранит email сотрудников,
— Age — столбец с возрастом сотрудников. */
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NOT NULL,
Age INT NOT NULL,
Email VARCHAR(100) NOT NULL
);Ограничение уникальности
Ограничение UNIQUE используется для того, чтобы гарантировать уникальность значений в столбцах. Например, если значения в столбце Email должны быть не только NOT NULL, но и уникальными, запрос будет выглядеть так:
/* Создание таблицы Employees с ограничением уникальности и NOT NULL.
Где:
— EmployeeID — уникальный идентификатор сотрудника,
— FirstName — столбец с типом данных «строка» (ячейка объемом до 50 символов), который будет хранить имена сотрудников,
— LastName — столбец с типом данных «строка» (ячейка объемом до 50 символов), который будет хранить фамилии сотрудников,
— Email — столбец с типом данных «строка» (ячейка объемом до 100 символов), который хранит email сотрудников,
— Age — столбец, который будет хранить возраст сотрудников. */
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Age INT,
Email VARCHAR(100) UNIQUE NOT NULL
);Primary Key Constraint
Ограничение PRIMARY KEY используется для уникальной идентификации каждой записи в таблице. Ограничение первичного ключа предотвращает дублирование информации и гарантирует, что значения в столбце (или группе столбцов) не будут пустыми (NULL).
Создадим еще одну таблицу Departments со столбцами DepartmentID и DepartmentName:
/* Создание таблицы Departments с первичным ключом в столбце DepartmentID.
Где:
— DepartmentID — уникальный идентификатор отдела,
— DepartmentName — столбец с названиями отделов и типом данных «строка» (ячейка объемом до 50 символов). */
CREATE TABLE Departments (
DepartmentID INT PRIMARY KEY,
DepartmentName VARCHAR(50)
);Foreign Key Constraint
Внешний ключ определяет связь между столбцами дочерней таблицы и столбцами родительской таблицы.
Родительская таблица — это таблица, которая содержит первичный ключ или уникальный идентификатор каждой записи. Другие таблицы, связанные с ней, ссылаются на ее первичный ключ через внешний.
Дочерняя таблица — это таблица, которая содержит внешний ключ и с его помощью ссылается на первичный ключ родительской таблицы.
Создадим связь между таблицами Employees (дочерняя) и Departments (родительская):
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Age INT,
Email VARCHAR(100),
DepartmentID INT,
FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID)
);Где:
— DepartmentID — столбец, который будет хранить идентификаторы отделов, к которым прикреплены сотрудники,
— FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID) — запрос для определения внешнего ключа.
Значения в столбце DepartmentID в таблице Employees будут ссылаться на существующие значения в столбце DepartmentID таблицы Departments. То есть каждый отдел в таблице Employees должен существовать в таблице Departments.
Ограничение CHECK
CHECK проверяет, соответствуют ли значения в столбце заданным условиям, и запрещает вставку или обновление строк, которые не соответствуют этим условиям. Для примера создадим ограничение столбце Age, которое будет гарантировать, что возраст сотрудников больше или равен 18:
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Age INT CHECK (Age >= 18)
);Ограничение DEFAULT
DEFAULT определяет для столбца значение по умолчанию. То есть, если вставляемая строка не содержит значения для этого столбца, будет использоваться значение по умолчанию. DEFAULT можно применять к любому столбцу, независимо от его типа данных.
Пример использования ограничения:
/* Создание таблицы Employees.
Где:
— EmployeeID — уникальный идентификатор сотрудника,
— FirstName — столбец с типом данных «строка» (ячейка объемом до 50 символов), который будет хранить имена сотрудников,
— LastName — столбец с типом данных «строка» (ячейка объемом до 50 символов), который будет хранить фамилии сотрудников,
— Email — столбец с типом данных «строка» (ячейка объемом до 100 символов), который хранит email сотрудников,
— Age — столбец, который будет хранить возраст сотрудников. */
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Email VARCHAR(100) DEFAULT 'test@reg.ru,
Age INT DEFAULT 30
);Если при вставке новой строки не указать значения в столбцах Email и Age, они будут заполнены автоматически: вместо email будет указан стандартный test@reg.ru, а возраст будет равен 30.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊